الذكاء الاصطناعي والشعر: مراجعة أدبية مقارنة لأحدث 10 دراسات محكَّمة
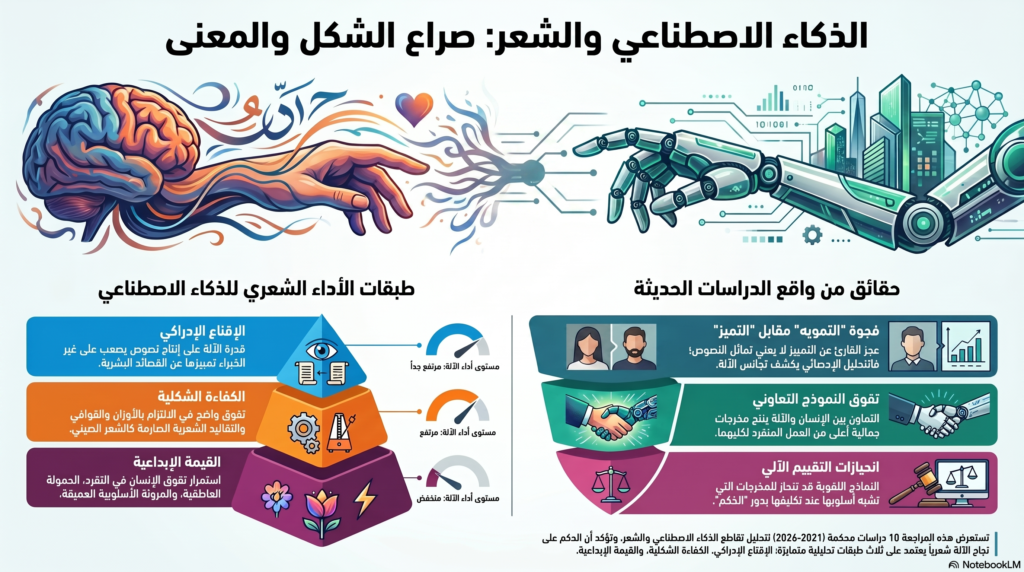
يتناول هذا المقال تقاطع الذكاء الاصطناعي والشعر بوصفه حقلاً فرعياً يتسارع تشكّله عند ملتقى الدراسات الأدبية والإنسانيات الرقمية وعلوم اللغة الحاسوبية. وتعتمد المراجعة مدونة نهائية تضم عشرة مقالات محكَّمة. ولا ترمي هذه المراجعة إلى تقديم ملخصات منفصلة لكل دراسة، بقدر ما تستهدف بناء قراءة مقارنة تُظهر مواطن الاتفاق والاختلاف في الأدبيات الحديثة عبر ثمانية محاور مترابطة: سؤال البحث، واللغة والمدونة الشعرية، ونوع الذكاء الاصطناعي، والمنهج، وأدوات القياس، والنتائج، ومفهوم الإبداع الشعري، ثم الأبعاد الأخلاقية والتربوية. وتنطلق المراجعة من افتراض مؤداه أن جانباً مهماً من التناقضات الظاهرة في الأدبيات يخفّ إذا جرى التمييز بين ثلاث طبقات تحليلية: الإقناع الإدراكي، والكفاءة الشكلية، والقيمة الشعرية/الإبداعية. وتخلص المقارنة إلى أن الأدبيات المحكمة الحديثة لا تتيح حكماً بسيطاً في مسألة قدرة الذكاء الاصطناعي على كتابة الشعر؛ لأن النتائج تختلف باختلاف الطبقة التحليلية المعتمدة. فعلى مستوى الإقناع الإدراكي، تبدو النماذج قادرة على إنتاج نصوص يصعب على غير الخبراء تمييزها من النصوص البشرية. وعلى مستوى الكفاءة الشكلية، يظهر تقدم واضح في التعامل مع الأوزان والقوافي وبعض التقاليد الشعرية الصارمة. أما على مستوى القيمة الشعرية/الإبداعية، فتظل الصورة أكثر تحفظاً، مع استمرار تفوق الإنسان في التفرد، والحمولة العاطفية، والصور الأدبية، والمرونة الأسلوبية.
الكلمات المفتاحية: الذكاء الاصطناعي؛ الشعر؛ النماذج اللغوية الكبرى؛ الإبداع الشعري؛ التقييم الأدبي؛ الإنسانيات الرقمية
مقدمة
غدا تقاطع الذكاء الاصطناعي والشعر، في السنوات القليلة الأخيرة، حقلاً فرعياً سريع التشكّل داخل الدراسات الأدبية والإنسانيات الرقمية وعلوم اللغة الحاسوبية. ولم يعد السؤال المطروح يقتصر على ما إذا كان النظام التوليدي قادراً على إنتاج نص موزون أو مقفّى أو مقنع على المستوى السطحي، بل انتقل إلى سؤال أكثر تركيباً: ما الذي تقيسه الدراسات، في الحقيقة، حين تتحدث عن نجاح الذكاء الاصطناعي شعرياً؟ وهل يكفي عجز القارئ غير الخبير عن التمييز بين القصيدة البشرية والقصيدة الاصطناعية للقول إن الآلة بلغت القيمة الشعرية نفسها، أم أن ما نرصده لا يتجاوز مستوى الإقناع الإدراكي أو الامتثال الشكلي؟
وتنبع أهمية هذا السؤال من أن الأدبيات الحديثة لا تعالج ظاهرة واحدة متجانسة، بل تتناول مستويات متباينة من الأداء الشعري والقراءة والتقييم. ومن ثم، فإن أي مراجعة مقارنة لهذا الحقل لا تستقيم من دون الانتباه إلى اختلاف أسئلة البحث، وأدوات القياس، وأنواع النماذج المدروسة، والسياقات اللغوية والثقافية التي تتحرك فيها القصيدة.
نطاق المراجعة ومنطقها التحليلي
تعتمد هذه المراجعة مدونة نهائية تضم عشرة مقالات محكَّمة نشرت بين 2021 و2026، وليست الغاية هنا أن نلخص كل دراسة على حدة، وإنما أن نبني قراءة مقارنة تكشف وجوه الاتفاق والاختلاف في الأدبيات الحديثة عبر ثمانية محاور مترابطة: سؤال البحث، واللغة والمدونة الشعرية، ونوع الذكاء الاصطناعي، والمنهج، وأدوات القياس، والنتائج، ومفهوم الإبداع الشعري، ثم الأبعاد الأخلاقية والتربوية.
وتفترض هذه المراجعة أن كثيراً من التناقضات الظاهرة في الأدبيات يخفّ إذا ميّزنا بين ثلاث طبقات تحليلية: الإقناع الإدراكي، أي قدرة النص الاصطناعي على أن يُستقبل بوصفه نصاً بشرياً أو على إرضاء القارئ غير الخبير؛ والكفاءة الشكلية، أي مدى الالتزام بالوزن والقافية والسمات الأسلوبية أو البنائية؛ والقيمة الشعرية/الإبداعية، أي ما يتصل بالتفرد، والكثافة الدلالية، والصدى العاطفي، والحمولة الثقافية، ومفهوم التأليف نفسه. وعلى هذا الأساس، لا تُقرأ الدراسات العشر بوصفها تتناول الشيء ذاته، بل بوصفها تختبر مستويات مختلفة من الظاهرة الشعرية.
التحليل المقارن
1. سؤال البحث ووظيفة الدليل
يتبين من المدونةأن الأدبيات لا تنتظم حول سؤال واحد، بل تتوزع على أسئلة معرفية متباينة تحدد، منذ البداية، ما الذي يُعد دليلاً صالحاً على النجاح أو الإخفاق. فالدراسات التجريبية المبكرة واللاحقة، مثل Köbis and Mossink (2021) وPorter and Machery (2024)، تنطلق أساساً من سؤال مفاده: هل يستطيع المتلقي العادي أن يميز بين القصيدة البشرية والقصيدة المولدة؟ وفي هذا المستوى، يكاد النجاح يساوي قدرة النص على اجتياز اختبار إدراكي. غير أن هذا النوع من الأسئلة يختلف جذرياً عن سؤال O’Sullivan (2025)، الذي لا يختبر القارئ، بل يختبر النص ذاته عبر مؤشرات أسلوبية تكشف مقدار تمايز الكتابة البشرية عن نواتج النماذج اللغوية.
وفي المقابل، تنتمي دراسات مثل Ma et al. (2026)، وTabassam et al. (2025)، وZhao et al. (2025) إلى منطق مغاير: فالمقصود فيها ليس معرفة ما إذا كان القارئ سيُخدع، بل ما إذا كان النموذج قادراً على إنجاز شروط شعرية مخصوصة داخل تقاليد لغوية وثقافية بعينها، كالشعر الصيني الكلاسيكي أو الشعر الأردي. وهنا يغدو النجاح أقرب إلى كفاءة توليدية تتصل بالنظام العروضي، والقافية، والتوازي، أو غيرها من القواعد. ثم تأتي Li et al. (2026) لتدفع النقاش خطوة أخرى إلى الأمام، إذ تنقل الحقل من سؤال الإنجاز الأحادي إلى سؤال التقييم متعدد الأبعاد: ما علاقة الدقة الشكلية بالإبداع، والتفرد، والصور الأدبية، والصدى العاطفي؟
أما Huang and Shea (2025) وHitsuwari et al. (2023)، فيعيدان صوغ المسألة من زاوية التأليف والجماليات والتعاون بين الإنسان والآلة؛ في حين تجعل Wang et al. (2025) من الذكاء الاصطناعي قضية تربوية تؤثر في تدريس الشعر ومهارات التذوق والنسبة. وعليه، فإن مقارنة النتائج من غير الانتباه إلى اختلاف سؤال البحث تؤدي إلى خلط منهجي؛ إذ ليس «عدم القدرة على التمييز» معادلاً لـ«تحقق الإبداع»، ولا «الالتزام بالوزن» دليلاً كافياً على «القيمة الشعرية».
2. اللغة والمدونة الشعرية والسياق الثقافي
تُظهر الدراسات العشر بوضوح أن اللغة ليست مجرد وعاء محايد تُسكب فيه القصيدة، بل عامل بنيوي يغيّر معنى النجاح وحدود الإخفاق في آن واحد. ففي الدراسات الإنجليزية التي تنشغل بالتلقي والتمييز، كما عند Köbis and Mossink (2021) وPorter and Machery (2024)، يدور السؤال أساساً حول استجابة القارئ غير الخبير لنصوص شعرية معاصرة نسبياً، يمكن تداولها داخل أفق قراءة عام. لكن المشهد يتبدل حين ننتقل إلى الصينية الكلاسيكية، كما في Ma et al. (2026) وZhao et al. (2025)، لأن القصيدة هناك لا تُقاس فقط بسلامة اللفظ أو بانسياب المعنى، بل تُحاكم أيضاً إلى تقاليد شكلية صارمة وإلى حمولة تاريخية وثقافية كثيفة. وعند هذا الحد يصبح الامتثال للقواعد شرطاً لازماً للحكم على الجودة، لكنه لا يعود شرطاً كافياً وحده.
وتؤكد دراسة Tabassam et al. (2025) هذه الفكرة من زاوية أخرى، حين تبرز خصوصية الشعر الأردي بوصفه ميداناً تتقاطع فيه اعتبارات الوزن مع محدودية الموارد الرقمية ومع ضرورة مراعاة الخصائص الثقافية للنص. وما توحي به هذه المقارنة هو أن أي تعميم كوني عن «قدرة» النماذج على كتابة الشعر يظل تعميماً متعجلاً ما لم يُربط بنوع المدونة الشعرية وبمقدار ما تستلزمه من معرفة شكلية وثقافية متخصصة. فالشعر الحر في الإنجليزية ليس نظيراً مباشراً لشعر التانغ، والهايكو الياباني الذي تناولته Hitsuwari et al. (2023) لا يشبه قصيدة تقوم على نظام عروضي كثيف أو على تراث بلاغي ممتد.
كما تفيد المقارنة بأن الفجوة بين الكفاءة الشكلية والقيمة الشعرية تتسع عادة كلما كانت القصيدة أشد تجذراً في تقليد مخصوص. ففي بعض السياقات الإنجليزية قد يمر النص بسبب قدرته على إنتاج سلاسة دلالية وإيقاع سطحي مقبول؛ أما في الشعر الصيني الكلاسيكي أو الأردي، فإن الانكشاف يظل أكثر احتمالاً عند مستويات أعمق تتصل بالقواعد الدقيقة والعلاقات الثقافية التي يحملها النص. وهذا يفسر لماذا تبدو بعض النماذج ناجحة في التلقي الأولي، في حين تتطلب دراسات التوليد المتخصص بروتوكولات تقييم أدق وأكثر صرامة (Ma et al., 2026; Zhao et al., 2025).
3. نوع الذكاء الاصطناعي والمنهج
تختلف المدونة كذلك من حيث نوع الذكاء الاصطناعي الموظف، ومن حيث الدور الذي يؤديه داخل كل دراسة. فـKöbis and Mossink (2021) تمثلان مرحلة مبكرة نسبياً يُختبر فيها نموذج عام مثل GPT-2 بوصفه مولداً لنصوص يُراد قياس قابلية القارئ لتمييزها. أما Porter and Machery (2024) فيوسّعان هذا المنطق تجريبياً على نطاق أكبر، بحيث تصبح النتيجة الإحصائية نفسها جزءاً من الحجة: فالقارئ غير الخبير لا ينجح في الفرز، بل قد ينسب بعض القصائد الاصطناعية إلى بشر ويفضّلها في بعض السمات.
غير أن O’Sullivan (2025) يبيّن أن «فشل القارئ» لا يعني بالضرورة تماثل النصوص. فالتحليل الأسلوبي الكمي قادر على التقاط فروق ملموسة بين الكتابة البشرية ونواتج GPT-3.5 وGPT-4 وLlama. وهذه نقطة منهجية أساسية، لأن النص قد يكون مقنعاً على المستوى الإدراكي، لكنه يظل قابلاً للكشف إحصائياً. ومن ثم، فإن نوع الذكاء الاصطناعي لا يُفهم هنا بوصفه آلة كتابة فحسب، بل قد يكون موضوعاً للمقارنة الأسلوبية أو أداةً للقياس داخل تصميم الدراسة نفسه.
وتغدو هذه المفارقة أوضح في Li et al. (2026)، حيث لا تؤدي النماذج دور المولد فقط، بل تدخل أيضاً في بنية التقييم عبر LLM-as-a-judge إلى جانب القواعد الآلية والتحقق البشري. ومعنى ذلك أن الحقل لم يعد يختبر قدرة النموذج على الإنتاج وحسب، بل صار يختبر أيضاً مدى صلاحية الاعتماد عليه في الحكم. وهنا تتقاطع هذه الدراسة مع Ma et al. (2026)، التي تنبّه إلى انحيازات التقييم عندما تتولى النماذج تقدير مخرجات شعرية تشبه، من حيث المبدأ، ما تنتجه هي نفسها.
أما في Zhao et al. (2025) وTabassam et al. (2025)، فنحن بإزاء نماذج متخصصة أو مطوَّعة للتعامل مع الشعر بوصفه شكلاً لغوياً ذا قيود دقيقة، وهو ما يختلف عن استخدام النماذج واسعة الغرض في التوليد العام. ومن ثم تكشف المقارنة أن الحديث عن «الذكاء الاصطناعي» بصيغة الكتلة الواحدة حديث مضلل؛ لأن النتائج تتبدل بتبدل موقع النموذج في الدراسة: مولِّداً، أو كاشفاً، أو حَكَماً، أو شريكاً في الكتابة.
4. أدوات القياس وطبيعة النتائج
إذا كان اختلاف سؤال البحث يحدد نوع الدليل، فإن اختلاف أدوات القياس يحدد أيضاً معنى «النجاح» ذاته. ففي دراسات التلقي، تقوم الحجة على اختبارات التمييز البشري والتفضيل الجمالي. وقد أظهرت دراسات Köbis and Mossink (2021)، وPorter and Machery (2024)، وHitsuwari et al. (2023) نمطاً متقارباً: فالقراء غير الخبراء يجدون صعوبة في التفريق بين القصائد البشرية والاصطناعية، وفي بعض السياقات قد يحوز النص الاصطناعي أو النص التعاوني تقديراً جمالياً مرتفعاً. لكن هذه النتيجة لا ينبغي أن تُقرأ بوصفها حكماً نهائياً على القيمة الأدبية، بل بوصفها مؤشراً إلى قوة الإقناع الإدراكي عند مستوى التلقي الأولي.
وتأتي نتائج O’Sullivan (2025) لتعقّد هذا الاستنتاج، إذ تكشف أدوات الأسلوبية أن النصوص الاصطناعية أكثر تجانساً، وأن الكتابة البشرية أوسع تنوعاً من حيث السمات الأسلوبية. وبذلك يصبح عجز القارئ غير الخبير عن التمييز دليلاً على حدود الإدراك العام، لا على غياب الفروق النصية نفسها. ومن هنا تتبلور إحدى أهم خلاصات الأدبيات: التمويه الإدراكي والتميّز الأسلوبي ليسا شيئاً واحداً.
وفي محور التوليد المتخصص، تُظهر دراسات Ma et al. (2026)، وTabassam et al. (2025)، وZhao et al. (2025) أن النماذج تستطيع تحقيق كفاءة شكلية معتبرة، ولا سيما حين تُدرَّب أو تُطوَّع للتعامل مع قواعد واضحة مثل النبرات، والقافية، والتوازي، والوزن. ويبدو هذا النجاح جلياً في Zhao et al. (2025)، حيث يحقق النموذج المتخصص تقدماً في توليد شعر التانغ الموزون عبر منظومة تعلم معزز واسترجاع معزز ونظام تقييم رباعي. كما تؤكد دراسة Tabassam et al. (2025) أهمية نمذجة الوزن الشعري في الأردية، بما يبرهن أن جزءاً مهماً من قابلية الذكاء الاصطناعي للنجاح يكمن في إمكان تحويل بعض شروط الشعر إلى قواعد قابلة للحوسبة.
غير أن Li et al. (2026) تكشف حدود هذا النجاح حين توسّع أفق التقييم. فالدراسة، التي قارنت طيفا واسعاً من القصائد البشرية ونواتج ثلاثين نموذجاً، تبيّن أن أفضلية النماذج في الدقة الشكلية أو اتباع التعليمات لا تتحول تلقائياً إلى تفوق في الإبداع، أو التفرد الأسلوبي، أو الصور الأدبية، أو الصدى العاطفي. بل إن التفوق البشري يظهر بوضوح أكبر كلما انتقلنا من القياس الشكلي إلى مؤشرات أعمق تتصل بالقيمة الشعرية. وبهذا المعنى تمنحنا Li et al. (2026) الإطار الأكثر صراحة لتمييز الطبقات الثلاث: فقد ينجح النموذج في الإقناع، وقد ينجح في الشكل، لكن ذلك لا يكفل له بالضرورة نجاحاً إبداعياً.
5. مفهوم الإبداع الشعري
تكشف المدونة أن مفهوم الإبداع نفسه ليس معطى ثابتاً تُستخلص نتائجه بسهولة، بل موضع خلاف نظري ومنهجي في آن واحد. فبعض الدراسات التجريبية تميل، ضمناً، إلى تعريف براغماتي للإبداع: إذا بدا النص مقنعاً للقارئ أو نال تفضيلاً جمالياً، فثمة مستوى معتبر من النجاح الأدائي (Köbis & Mossink, 2021; Porter & Machery, 2024). غير أن هذا التعريف يظل محدوداً من منظور الدراسات التي تمنح وزناً أكبر للتفرد، والحمولة العاطفية، والصور الأدبية المركبة، وتاريخية الصوت الشعري.
وهنا تبرز أهمية Huang and Shea (2025)، إذ تنقل النقاش من سؤال المنتج إلى سؤال المؤلف في سياق ما بعد الإنسانية. فالقصيدة، وفق هذا المنظور، ليست مجرد سلسلة لغوية قابلة للتحسين التقني، بل موضع تتداخل فيه الوكالة البشرية مع الوسيط الخوارزمي، بما يعيد النظر في مركزية الشاعر من دون أن يلغيها. وتدعم Hitsuwari et al. (2023) هذا الاتجاه من زاوية تجريبية، إذ تشير إلى أن التعاون بين الإنسان والذكاء الاصطناعي قد ينتج مخرجات تحظى بتقييمات جمالية أعلى من العمل البشري الخالص أو الاصطناعي الخالص. لكن هذه النتيجة لا تساوي بين الطرفين، بل ترجح نموذجاً تعاونياً يرى في الذكاء الاصطناعي أداة توسيع أو تحفيز، لا بديلاً كاملاً عن الخبرة الشعرية.
وفي المقابل، تدفع نتائج Li et al. (2026) وO’Sullivan (2025) نحو موقف أكثر تفريقاً وحذراً. فثمة مؤشرات قوية إلى أن النصوص الاصطناعية، رغم قدرتها على الامتثال والإقناع، ما تزال أقل تفرداً، وأكثر تجانساً أسلوبياً، وأضعف في بعض مؤشرات الإبداع العميق. وعليه، يبدو أن الأدبيات لا تسند حكماً ثنائياً من قبيل «الآلة مبدعة» أو «الآلة غير مبدعة»، بل تكشف أن الإبداع الشعري مفهوم متعدد الطبقات: فقد يتحقق بعضه على مستوى الأداء أو التنويع أو التحفيز، بينما يظل بعضه الآخر مشدوداً إلى الذاتية، والخبرة التاريخية، والاختيار الأسلوبي المتفرد.
6. الأبعاد الأخلاقية والتربوية
لا تبدو القضايا الأخلاقية والتربوية في هذه الأدبيات ملحقاً خارجياً يمكن تأجيله، بل جزءاً من تعريف النجاح نفسه. فقد بيّنت Hitsuwari et al. (2023) أن معرفة المتلقي بمصدر النص تؤثر في حكمه الجمالي، بما يكشف أثر «نفور الخوارزمية» أو التحيز ضد العمل عندما يُوسَم بأنه اصطناعي. وهذا يعني أن تلقي القصيدة لا يتحدد بخصائصها النصية وحدها، بل يتأثر أيضاً بسياق الإسناد وبدرجة الشفافية المصاحبة لها.
وتضيف Ma et al. (2026) بعداً أخلاقياً آخر يتمثل في انحيازات التقييم عندما تصبح النماذج نفسها أدوات للحكم على الشعر. فالمسألة هنا لا تمس الدقة التقنية فقط، بل تمس كذلك عدالة التقييم ومعايير الشرعية النقدية. وإذا أضفنا إلى ذلك نتائج Wang et al. (2025)، اتضح أن الذكاء الاصطناعي يفرض على تعليم الشعر معضلة مزدوجة: فهو قد ييسر الفهم والشرح والتفاعل مع النصوص، لكنه قد يهدد، في الوقت نفسه، مهارات القراءة البطيئة، والكتابة الأصيلة، والنسبة الواضحة للمؤلف، فضلاً عن احتمالات الانتحال أو الاتكال المفرط على الأداة.
ومن ثم، لا يمكن فصل السؤال الجمالي عن السؤال المؤسسي. فالقصيدة التي تبدو ناجحة داخل تجربة مخبرية قصيرة قد تكون أقل قبولاً، أو أكثر إشكالاً، داخل الصف الدراسي أو في ممارسات النشر والتأليف. ومن هنا تنبع أهمية الشفافية في نسبة العمل، وأهمية حضور الخبراء الأدبيين في التقييم، وأهمية التمييز بين استخدام الذكاء الاصطناعي بوصفه أداة مساعدة على الفهم أو التحرير، وبين استخدامه بديلاً عن الفعل الإبداعي نفسه.
مناقشة نقدية
تفضي المقارنة بين الدراسات العشر إلى نتيجة مركزية مفادها أن الأدبيات لا تتحدث عن «قدرة واحدة» للذكاء الاصطناعي على كتابة الشعر، بل عن قدرات متعددة تتوزع على ثلاث طبقات متمايزة. ففي طبقة الإقناع الإدراكي، تبدو النتائج لافتة بالفعل؛ إذ إن القارئ غير الخبير لا ينجح غالباً في التمييز، وقد يمنح بعض النصوص الاصطناعية أو التعاونية أحكاماً إيجابية (Hitsuwari et al., 2023; Köbis & Mossink, 2021; Porter & Machery, 2024). لكن هذه الطبقة، على أهميتها، تظل أضعف دلالة على القيمة الأدبية، لأنها تعتمد على استقبال سريع وغير متخصص، وتخلط أحياناً بين سهولة المعالجة الإدراكية وبين الجودة الشعرية نفسها.
وفي طبقة الكفاءة الشكلية، تكشف الأدبيات التقنية أن النماذج صارت أكثر قدرة على التعامل مع القيود الشعرية الصريحة، ولا سيما في السياقات التي يمكن فيها تقنين المعايير، كما في شعر التانغ أو في بعض أنماط الوزن الأردي (Ma et al., 2026; Tabassam et al., 2025; Zhao et al., 2025). غير أن هذا النجاح يظل مشروطاً بوجود بنية قابلة للترميز وبوجود مقاييس واضحة نسبياً، وهو ما يجعل الإنجاز أقوى في الامتثال منه في الابتكار.
أما طبقة القيمة الشعرية/الإبداعية، فهي موضع النزاع الحقيقي. فحين تنتقل أدوات القياس من مجرد التمييز أو الضبط الشكلي إلى مؤشرات مثل التفرد، والصور الأدبية، والصدى العاطفي، والتنوع الأسلوبي، يستعيد الإنسان تفوقاً ملحوظاً (Li et al., 2026; O’Sullivan, 2025). ولا يعني ذلك أن الذكاء الاصطناعي عاجز عن أي مساهمة إبداعية، بل يعني أن ما ينتجه يحتاج إلى فهم أدق لحدود المصطلحات: فهناك فرق بين قصيدة «صالحة للقراءة»، وقصيدة «منضبطة شكلياً»، وقصيدة «ذات قيمة شعرية عالية».
ومن الناحية المنهجية، تكشف هذه الأدبيات فجوة ثابتة بين ما يمكن قياسه بدقة وما يهم الأدب فعلاً. فالتجارب الإحصائية تمنحنا صلابة في وصف سلوك المتلقين، وأسلوبية توفر أدوات قوية لكشف الأنماط، والدراسات الهندسية تشرح كيف يمكن تحسين الأداء؛ إلا أن مفاهيم مثل الأصالة، والضرورة التعبيرية، والإقامة العاطفية الطويلة للنص، والحمولة الثقافية أو التاريخية، ما تزال عصية على الاختزال في مؤشرات كمية منفردة. لذلك تبدو أطر التقييم الهجينة، التي تجمع بين القياس الآلي والتحكيم البشري الخبير، أكثر إقناعاً من المقاييس الأحادية.
كما تكشف المراجعة ثغرات واضحة في الحقل. أول هذه الثغرات غياب الدراسات العربية المحكمة عن مقالات المدونة، وهو نقص معرفي مهم إذا أخذنا في الاعتبار غنى الشعر العربي من حيث العروض والبلاغة والتناص. وثانيها محدودية المقارنات العابرة للغات؛ إذ ما تزال الأدبيات تميل إلى دراسات حالة منفصلة أكثر من ميلها إلى بناء نظرية مقارنة للشعرية الحاسوبية عبر التقاليد المختلفة. وثالثها نقص الدراسات التي تدمج النقد الأدبي الصارم مع التصميم التجريبي القوي، بحيث لا يبقى الأدب مجرد حقل تطبيق للهندسة، ولا تبقى التقنية مجرد مناسبة لتأملات عامة حول المؤلف. ورابعها الحاجة إلى مساءلة بيانات التدريب نفسها: من أين تأتي المدونة الشعرية؟ وكيف يُعاد تمثيل التراث داخل نماذج قد تعيد إنتاجه بلا وعي تاريخي، أو بلا شفافية كافية في الملكية والإسناد؟
ومن هنا يمكن اقتراح أجندة بحثية مستقبلية في خمسة اتجاهات: أولاً، بناء بروتوكولات تقييم هجينة تجمع بين المعيار الشكلي، والتحليل الأسلوبي، والتحكيم الأدبي الخبير. ثانياً، توسيع البحث إلى الشعر العربي وغيره من التقاليد غير المهيمنة رقمياً. ثالثاً، التمييز تجريبياً بين القصيدة المولدة آلياً والقصيدة الناتجة عن تعاون إنسان/آلة، لأن النتائج الحالية توحي بأن التعاون قد يكون أكثر خصوبة من منطق الاستبدال. رابعاً، فحص انحيازات النماذج اللغوية الكبيرة عندما تكون حكما مقارنة بأحكام الشعراء والنقاد. خامساً، تطوير مدونة مرجعية مفتوحة ومتوازنة تسمح بمقارنات أكثر إنصافاً بين النماذج والبشر عبر لغات وأزمنة وأشكال شعرية متعددة.
خاتمة
تخلص هذه المراجعة إلى أن الأدبيات المحكمة الحديثة لا تسند حكماً بسيطاً في مسألة «هل يكتب الذكاء الاصطناعي شعراً؟». فالجواب يتوقف على الطبقة التحليلية التي نعتمدها. فعلى مستوى الإقناع الإدراكي، نجحت النماذج بوضوح في إنتاج نصوص يصعب على غير الخبراء تمييزها من النصوص البشرية، بل قد تُفضَّل أحياناً. وعلى مستوى الكفاءة الشكلية، أظهرت الدراسات التقنية تقدماً ملموساً في التعامل مع الأوزان والقوافي والتقاليد الشعرية المخصوصة. أما على مستوى القيمة الشعرية/الإبداعية، فتظل الصورة أكثر تحفظاً؛ إذ تشير الأدلة المقارنة إلى استمرار تفوق الإنسان في التفرد، والحمولة العاطفية، والصور الأدبية، والمرونة الأسلوبية، حتى حين تقترب النماذج من الإقناع أو الامتثال.
وبذلك، فإن الإسهام الأهم لهذه الأدبيات لا يتمثل في إعلان انتصار آلة على شاعر، بل في كشف تحول أعمق في شروط الكتابة الشعرية وتلقيها وتقييمها. فالمسألة لم تعد ثنائية بسيطة بين أصل ونسخة، أو بين بشر وآلة فحسب، بل صارت اختباراً لمفاهيم النقد نفسها: ما الذي نعدّه دليلاً على الإبداع؟ ومن يملك شرعية الحكم؟ وكيف تتغير صورة المؤلف حين تدخل الخوارزمية فضاء القصيدة؟ وهذه الأسئلة، أكثر من أي نتيجة تجريبية منفردة، هي ما يجعل حقل الذكاء الاصطناعي والشعر واحداً من أكثر حقول الأدب المعاصر إثارةً للحاجة إلى مراجعة نقدية متعددة التخصصات.
ثبت المراجع
Hitsuwari, J., Ueda, Y., Yun, W., & Nomura, M. (2023). Does human–AI collaboration lead to more creative art? Aesthetic evaluation of human-made and AI-generated haiku poetry. Computers in Human Behavior, 139, 107502.
Huang, Y., & Shea, J. (2025). Lyric poetry in the face of posthumanism: An analysis of generative AI-assisted poetry writing. In Proceedings of the 2025 Conference on Creativity and Cognition (C&C ’25). ACM.
Köbis, N., & Mossink, L. D. (2021). Artificial intelligence versus Maya Angelou: Experimental evidence that people cannot differentiate AI-generated from human-written poetry. Computers in Human Behavior, 114, 106553.
Li, B., Wang, H., & Wilkinson, H. (2026). POEMetric: The last stanza of humanity. In Proceedings of the International Conference on Learning Representations (ICLR 2026). OpenReview.
Ma, B., Yao, Y., & Haensch, A.-C. (2026). Capabilities and evaluation biases of large language models in classical Chinese poetry generation: A case study on Tang poetry. In Findings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026).
O’Sullivan, J. (2025). Stylometric comparisons of human versus AI-generated creative writing. Humanities and Social Sciences Communications, 12(1), Article 1708.
Porter, B., & Machery, E. (2024). AI-generated poetry is indistinguishable from human-written poetry and is rated more favorably. Scientific Reports, 14, Article 26133.
Tabassam, R., Hassan, S. U., Ahsan, A., & Zaman, F. (2025). UPON: Urdu poetry generation using deep learning: A novel approach and evaluation. ACM Transactions on Asian and Low-Resource Language Information Processing.
Wang, S. I. C., Wang, S. B., & Liu, E. Z. F. (2025). The impact of generative AI on Chinese poetry instruction. Social Sciences & Humanities Open.
Zhao, W., Wang, X., He, J., Zhao, Z., Liu, C., & Liu, L. (2025). Large language models learning to write rhyming Tang poetry: A Xunzi Yayun R1 case study. npj Heritage Science, 13, Article 519.